
Understanding Client-Side GraphQl With Apollo-Client In React Apps
According to State of JavaScript 2019, 38.7% of developers would like to use GraphQL, while 50.8% of developers would like to learn GraphQL.
Being a query language, GraphQL simplifies the workflow of building a client application. It removes the complexity of managing API endpoints in client-side apps because it exposes a single HTTP endpoint to fetch the required data. Hence, it eliminates overfetching and underfetching of data, as in the case of REST.
But GraphQL is just a query language. In order to use it easily, we need a platform that does the heavy lifting for us. One such platform is Apollo.
The Apollo platform is an implementation of GraphQL that transfers data between the cloud (the server) to the UI of your app. When you use Apollo Client, all of the logic for retrieving data, tracking, loading, and updating the UI is encapsulated by the useQuery hook (as in the case of React). Hence, data fetching is declarative. It also has zero-configuration caching. Just by setting up Apollo Client in your app, you get an intelligent cache out of the box, with no additional configuration required.
Apollo Client is also interoperable with other frameworks, such as Angular, Vue.js, and React.
Note: This tutorial will benefit those who have worked with RESTful or other forms of APIs in the past on the client-side and want to see whether GraphQL is worth taking a shot at. This means you should have worked with an API before; only then will you be able to understand how beneficial GraphQL could be to you. While we will be covering a few basics of GraphQL and Apollo Client, a good knowledge of JavaScript and React Hooks will come in handy.
GraphQL Basics
This article isn’t a complete introduction to GraphQL, but we will define a few conventions before continuing.
What Is GraphQL?
GraphQL is a specification that describes a declarative query language that your clients can use to ask an API for the exact data they want. This is achieved by creating a strong type schema for your API, with ultimate flexibility. It also ensures that the API resolves data and that client queries are validated against a schema. This definition means that GraphQL contains some specifications that make it a declarative query language, with an API that is statically typed (built around Typescript) and making it possible for the client to leverage those type systems to ask the API for the exact data it wants.
So, if we created some types with some fields in them, then, from the client-side, we could say, “Give us this data with these exact fields”. Then the API will respond with that exact shape, just as if we were using a type system in a strongly typed language. You can learn more in my Typescript article.
Let’s look at some conventions of GraphQl that will help us as we continue.
The Basics
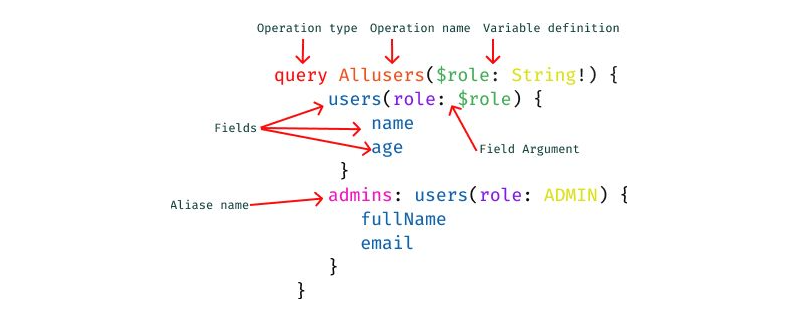
- Operations
In GraphQL, every action performed is called an operation. There are a few operations, namely:- Query
This operation is concerned with fetching data from the server. You could also call it a read-only fetch. - Mutation
This operation involves creating, updating, and deleting data from a server. It is popularly called a CUD (create, update, and delete) operation. - Subscriptions
This operation in GraphQL involves sending data from a server to its clients when specific events take place. They are usually implemented with WebSockets.
- Query
In this article, we will be dealing only with query and mutation operations.
- Operation names
There are unique names for your client-side query and mutation operations. - Variables and arguments
Operations can define arguments, very much like a function in most programming languages. Those variables can then be passed to query or mutation calls inside the operation as arguments. Variables are expected to be given at runtime during the execution of an operation from your client. - Aliasing
This is a convention in client-side GraphQL that involves renaming verbose or vague field names with simple and readable field names for the UI. Aliasing is necessary in use cases where you don’t want to have conflicting field names.
What Is Client-Side GraphQL?
When a front-end engineer builds UI components using any framework, like Vue.js or (in our case) React, those components are modeled and designed from a certain pattern on the client to suit the data that will be fetched from the server.
One of the most common problems with RESTful APIs is overfetching and underfetching. This happens because the only way for a client to download data is by hitting endpoints that return fixed data structures. Overfetching in this context means that a client downloads more information than is required by the app.
In GraphQL, on the other hand, you’d simply send a single query to the GraphQL server that includes the required data. The server would then respond with a JSON object of the exact data you’ve requested — hence, no overfetching. Sebastian Eschweiler explains the differences between RESTful APIs and GraphQL.
Client-side GraphQL is a client-side infrastructure that interfaces with data from a GraphQL server to perform the following functions:
- It manages data by sending queries and mutating data without you having to construct HTTP requests all by yourself. You can spend less time plumbing data and more time building the actual application.
- It manages the complexity of a cache for you. So, you can store and retrieve the data fetched from the server, without any third-party interference, and easily avoid refetching duplicate resources. Thus, it identifies when two resources are the same, which is great for a complex app.
- It keeps your UI consistent with Optimistic UI, a convention that simulates the results of a mutation (i.e. the created data) and updates the UI even before receiving a response from the server. Once the response is received from the server, the optimistic result is thrown away and replaced with the actual result.
For further information about client-side GraphQL, spare an hour with the cocreator of GraphQL and other cool folks on GraphQL Radio.
What Is Apollo Client?
Apollo Client is an interoperable, ultra-flexible, community-driven GraphQL client for JavaScript and native platforms. Its impressive features include a robust state-management tool (Apollo Link), a zero-config caching system, a declarative approach to fetching data, easy-to-implement pagination, and the Optimistic UI for your client-side application.
Apollo Client stores not only the state from the data fetched from the server, but also the state that it has created locally on your client; hence, it manages state for both API data and local data.
It’s also important to note that you can use Apollo Client alongside other state-management tools, like Redux, without conflict. Plus, it’s possible to migrate your state management from, say, Redux to Apollo Client (which is beyond the scope of this article). Ultimately, the main purpose of Apollo Client is to enable engineers to query data in an API seamlessly.
Features of Apollo Client
Apollo Client has won over so many engineers and companies because of its extremely helpful features that make building modern robust applications a breeze. The following features come baked in:
- Caching
Apollo Client supports caching on the fly. - Optimistic UI
Apollo Client has cool support for the Optimistic UI. It involves temporarily displaying the final state of an operation (mutation) while the operation is in progress. Once the operation is complete, the real data replaces the optimistic data. - Pagination
Apollo Client has built-in functionality that makes it quite easy to implement pagination in your application. It takes care of most of the technical headaches of fetching a list of data, either in patches or at once, using thefetchMorefunction, which comes with theuseQueryhook.
In this article, we will look at a selection of these features.
Enough of the theory. Tighten your seat belt and grab a cup of coffee to go with your pancakes, as we get our hands dirty.
Building Our Web App
This project is inspired by Scott Moss.
We will be building a simple pet shop web app, whose features include:
- fetching our pets from the server-side;
- creating a pet (which involves creating the name, type of pet, and image);
- using the Optimistic UI;
- using pagination to segment our data.
To begin, clone the repository, ensuring that the starter branch is what you’ve cloned.
Getting Started
- Install the Apollo Client Developer Tools extension for Chrome.
- Using the command-line interface (CLI), navigate to the directory of the cloned repository, and run the command to get all dependencies:
npm install. - Run the command
npm run appto start the app. - While still in the root folder, run the command
npm run server. This will start our back-end server for us, which we’ll use as we proceed.
The app should open up in a configured port. Mine is http://localhost:1234/; yours is probably something else.
If everything worked well, your app should look like this:
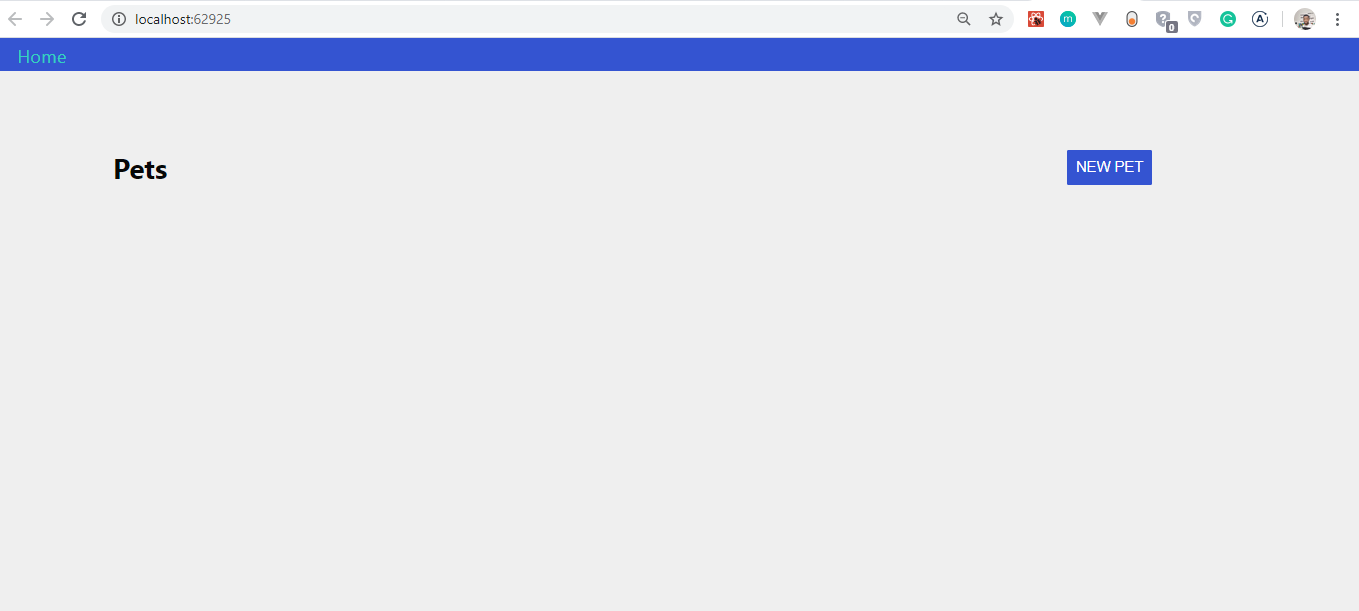
You’ll notice that we’ve got no pets to display. That’s because we haven’t created such functionality yet.
If you’ve installed Apollo Client Developer Tools correctly, open up the developer tools and click on the tray icon. You’ll see “Apollo” and something like this:
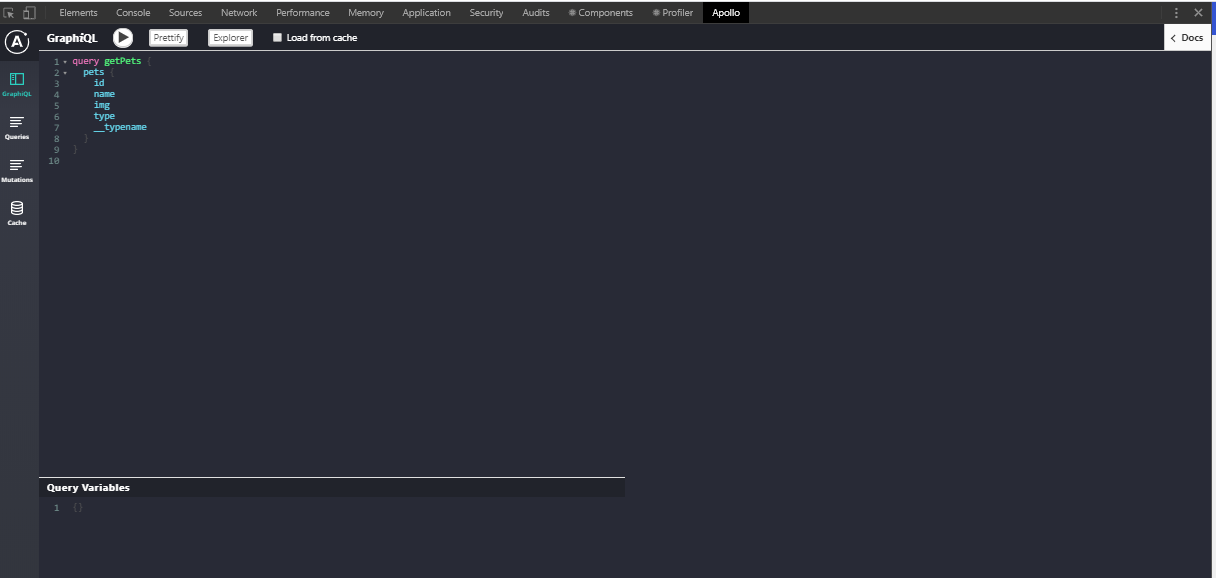
Like the Redux and React developer tools, we will be using Apollo Client Developer Tools to write and test our queries and mutations. The extension comes with the GraphQL Playground.
Fetching Pets
Let’s add the functionality that fetches pets. Move over to client/src/client.js. We’ll be writing Apollo Client, linking it to an API, exporting it as a default client, and writing a new query.
Copy the following code and paste it in client.js:
import { ApolloClient } from 'apollo-client' import { InMemoryCache } from 'apollo-cache-inmemory' import { HttpLink } from 'apollo-link-http' const link = new HttpLink({ uri: 'https://localhost:4000/' }) const cache = new InMemoryCache() const client = new ApolloClient({ link, cache }) export default clientHere’s an explanation of what is happening above:
ApolloClient
This will be the function that wraps our app and, thus, interfaces with the HTTP, caches the data, and updates the UI.InMemoryCache
This is the normalized data store in Apollo Client that helps with manipulating the cache in our application.HttpLink
This is a standard network interface for modifying the control flow of GraphQL requests and fetching GraphQL results. It acts as middleware, fetching results from the GraphQL server each time the link is fired. Plus, it’s a good substitute for other options, likeAxiosandwindow.fetch.- We declare a link variable that is assigned to an instance of
HttpLink. It takes auriproperty and a value to our server, which ishttps://localhost:4000/. - Next is a cache variable that holds the new instance of
InMemoryCache. - The client variable also takes an instance of
ApolloClientand wraps thelinkandcache. - Lastly, we export the
clientso that we can use it across the application.
Before we get to see this in action, we’ve got to make sure that our entire app is exposed to Apollo and that our app can receive data fetched from the server and that it can mutate that data.
To achieve this, let’s head over to client/src/index.js:
import React from 'react' import ReactDOM from 'react-dom' import { BrowserRouter } from 'react-router-dom' import { ApolloProvider } from '@apollo/react-hooks' import App from './components/App' import client from './client' import './index.css' const Root = () => ( <BrowserRouter><ApolloProvider client={client}> <App /> </ApolloProvider></BrowserRouter> ); ReactDOM.render(<Root />, document.getElementById('app')) if (module.hot) { module.hot.accept() }
As you’ll notice in the highlighted code, we’ve wrapped the App component in ApolloProvider and passed the client as a prop to the client. ApolloProvider is similar to React’s Context.Provider. It wraps your React app and places the client in context, which allows you to access it from anywhere in your component tree.
To fetch our pets from the server, we need to write queries that request the exact fields that we want. Head over to client/src/pages/Pets.js, and copy and paste the following code into it:
import React, {useState} from 'react' import gql from 'graphql-tag' import { useQuery, useMutation } from '@apollo/react-hooks' import PetsList from '../components/PetsList' import NewPetModal from '../components/NewPetModal' import Loader from '../components/Loader'const GET_PETS = gqlquery getPets { pets { id name type img } };export default function Pets () { const [modal, setModal] = useState(false)const { loading, error, data } = useQuery(GET_PETS); if (loading) return <Loader />; if (error) return <p>An error occured!</p>;const onSubmit = input => { setModal(false) } if (modal) { return <NewPetModal onSubmit={onSubmit} onCancel={() => setModal(false)} /> } return ( <div className="page pets-page"> <section> <div className="row betwee-xs middle-xs"> <div className="col-xs-10"> <h1>Pets</h1> </div> <div className="col-xs-2"> <button onClick={() => setModal(true)}>new pet</button> </div> </div> </section> <section><PetsList pets={data.pets}/></section> </div> ) }
With a few bits of code, we are able to fetch the pets from the server.
What Is gql?
It’s important to note that operations in GraphQL are generally JSON objects written with graphql-tag and with backticks.
gql tags are JavaScript template literal tags that parse GraphQL query strings into the GraphQL AST (abstract syntax tree).
- Query operations
In order to fetch our pets from the server, we need to perform a query operation.- Because we’re making a
queryoperation, we needed to specify thetypeof operation before naming it. - The name of our query is
GET_PETS. It’s a naming convention of GraphQL to use camelCase for field names. - The name of our fields is
pets. Hence, we specify the exact fields that we need from the server(id, name, type, img). useQueryis a React hook that is the basis for executing queries in an Apollo application. To perform a query operation in our React component, we call theuseQueryhook, which was initially imported from@apollo/react-hooks. Next, we pass it a GraphQL query string, which isGET_PETSin our case.
- Because we’re making a
- When our component renders,
useQueryreturns an object response from Apollo Client that contains loading, error, and data properties. Thus, they are destructured, so that we can use them to render the UI. useQueryis awesome. We don’t have to includeasync-await. It’s already taken care of in the background. Pretty cool, isn’t it?loading
This property helps us handle the loading state of the application. In our case, we return aLoadercomponent while our application loads. By default, loading isfalse.error
Just in case, we use this property to handle any error that might occur.data
This contains our actual data from the server.- Lastly, in our
PetsListcomponent, we pass thepetsprops, withdata.petsas an object value.
At this point, we have successfully queried our server.
To start our application, let’s run the following command:
- Start the client app. Run the command
npm run appin your CLI. - Start the server. Run the command
npm run serverin another CLI.
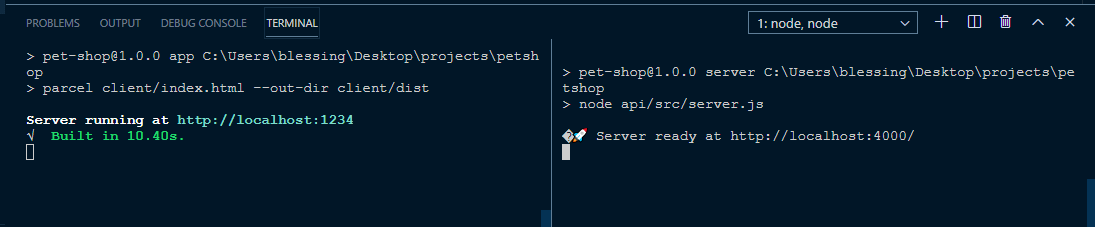
If all went well, you should see this:
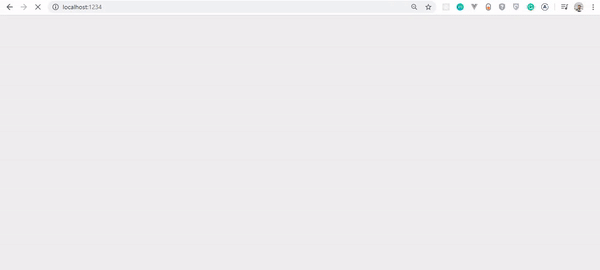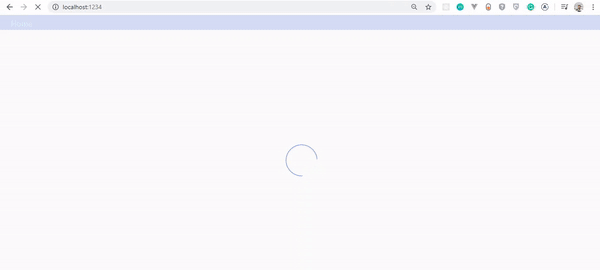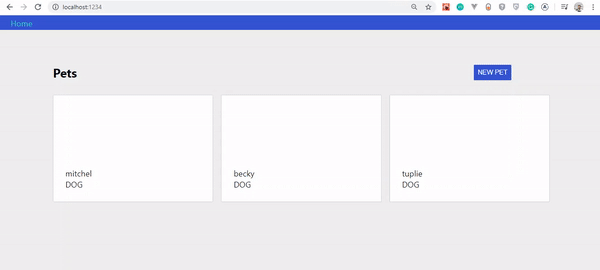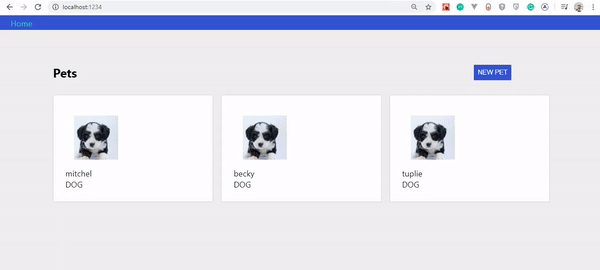 Pets queried from the server.
Pets queried from the server.
Mutating Data
Mutating data or creating data in Apollo Client is almost the same as querying data, with very slight changes.
Still in client/src/pages/Pets.js, let’s copy and paste the highlighted code:
.... const GET_PETS = gql` query getPets { pets { id name type img } } `;const NEW_PETS = gql` mutation CreateAPet($ newPet: NewPetInput!) { addPet(input: $ newPet) { id name type img } } `;const Pets = () => { const [modal, setModal] = useState(false) const { loading, error, data } = useQuery(GET_PETS);const [createPet, newPet] = useMutation(NEW_PETS);const onSubmit = input => { setModal(false)createPet({ variables: { newPet: input } }); } if (loading || newPet.loading) return <Loader />; if (error || newPet.error) return <p>An error occured</p>;if (modal) { return <NewPetModal onSubmit={onSubmit} onCancel={() => setModal(false)} /> } return ( <div className="page pets-page"> <section> <div className="row betwee-xs middle-xs"> <div className="col-xs-10"> <h1>Pets</h1> </div> <div className="col-xs-2"> <button onClick={() => setModal(true)}>new pet</button> </div> </div> </section> <section> <PetsList pets={data.pets}/> </section> </div> ) } export default Pets
To create a mutation, we would take the following steps.
1. mutation
To create, update, or delete, we need to perform the mutation operation. The mutation operation has a CreateAPet name, with one argument. This argument has a $ newPet variable, with a type of NewPetInput. The ! means that the operation is required; thus, GraphQL won’t execute the operation unless we pass a newPet variable whose type is NewPetInput.
2. addPet
The addPet function, which is inside the mutation operation, takes an argument of input and is set to our $ newPet variable. The field sets specified in our addPet function must be equal to the field sets in our query. The field sets in our operation are:
idnametypeimg
3. useMutation
The useMutation React hook is the primary API for executing mutations in an Apollo application. When we need to mutate data, we call useMutation in a React component and pass it a GraphQL string (in our case, NEW_PETS).
When our component renders useMutation, it returns a tuple (that is, an ordered set of data constituting a record) in an array that includes:
- a
mutatefunction that we can call at any time to execute the mutation; - an object with fields that represent the current status of the mutation’s execution.
The useMutation hook is passed a GraphQL mutation string (which is NEW_PETS in our case). We destructured the tuple, which is the function (createPet) that will mutate the data and the object field (newPets).
4. createPet
In our onSubmit function, shortly after the setModal state, we defined our createPet. This function takes a variable with an object property of a value set to { newPet: input }. The input represents the various input fields in our form (such as name, type, etc.).
With that done, the outcome should look like this:
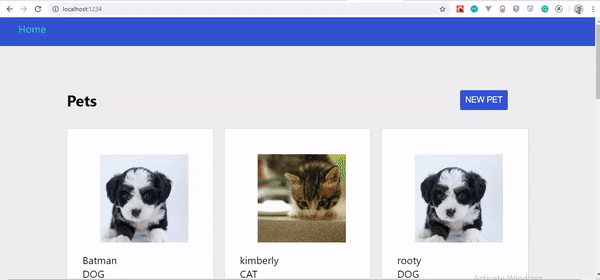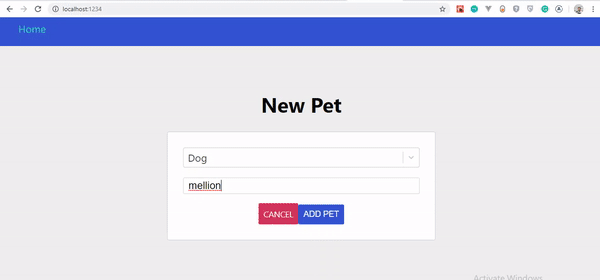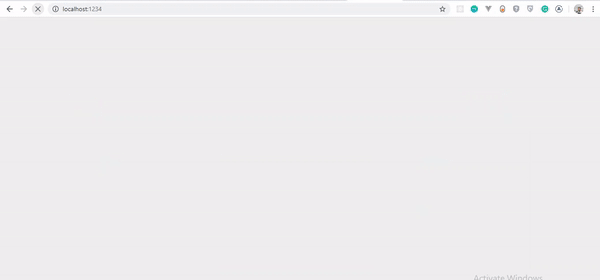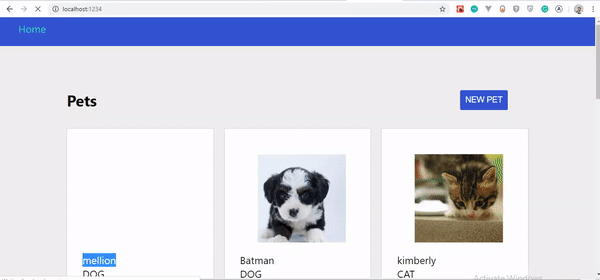 Mutation without instant update.
Mutation without instant update.
If you observe the GIF closely, you’ll notice that our created pet doesn’t show up instantly, only when the page is refreshed. However, it has been updated on the server.
The big question is, why doesn’t our pet update instantly? Let’s find out in the next section.
Caching In Apollo Client
The reason our app doesn’t update automatically is that our newly created data doesn’t match the cache data in Apollo Client. So, there is a conflict as to what exactly it needs to be updated from the cache.
Simply put, if we perform a mutation that updates or deletes multiple entries (a node), then we are responsible for updating any queries referencing that node, so that it modifies our cached data to match the modifications that a mutation makes to our back-end data.
Keeping Cache In Sync
There are a few ways to keep our cache in sync each time we perform a mutation operation.
The first is by refetching matching queries after a mutation, using the refetchQueries object property (the simplest way).
Note: If we were to use this method, it would take an object property in our createPet function called refetchQueries, and it would contain an array of objects with a value of the query: refetchQueries: [{ query: GET_PETS }].
Because our focus in this section isn’t just to update our created pets in the UI, but to manipulate the cache, we won’t be using this method.
The second approach is to use the update function. In Apollo Client, there’s an update helper function that helps modify the cache data, so that it syncs with the modifications that a mutation makes to our back-end data. Using this function, we can read and write to the cache.
Updating The Cache
Copy the following highlighted code, and paste it in client/src/pages/Pets.js:
...... const Pets = () => { const [modal, setModal] = useState(false) const { loading, error, data } = useQuery(GET_PETS);const [createPet, newPet] = useMutation(NEW_PETS, { update(cache, { data: { addPet } }) { const data = cache.readQuery({ query: GET_PETS }); cache.writeQuery({ query: GET_PETS, data: { pets: [addPet, ...data.pets] }, }); }, } );.....
The update function receives two arguments:
- The first argument is the cache from Apollo Client.
- The second is the exact mutation response from the server. We destructure the
dataproperty and set it to our mutation (addPet).
Next, to update the function, we need to check for what query needs to be updated (in our case, the GET_PETS query) and read the cache.
Secondly, we need to write to the query that was read, so that it knows we’re about to update it. We do so by passing an object that contains a query object property, with the value set to our query operation (GET_PETS), and a data property whose value is a pet object and that has an array of the addPet mutation and a copy of the pet’s data.
If you followed these steps carefully, you should see your pets update automatically as you create them. Let’s take a look at the changes:
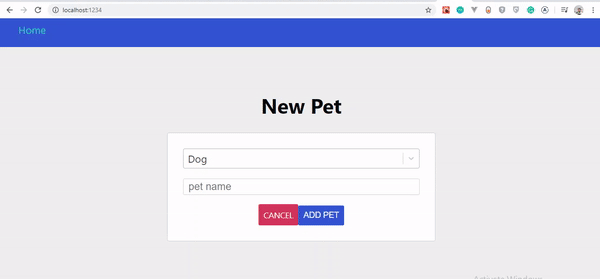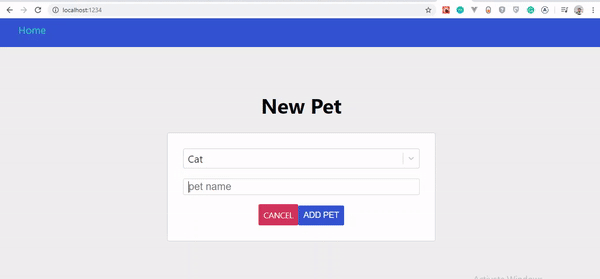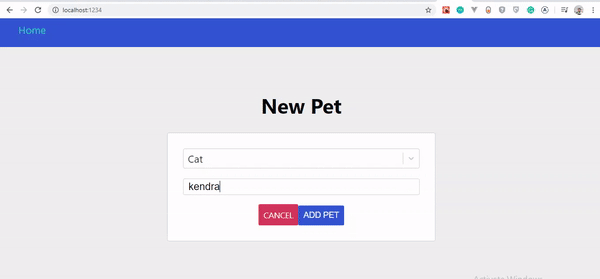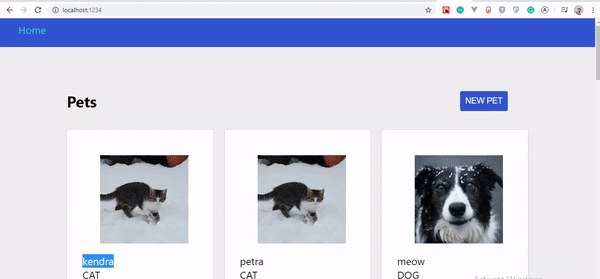 Pets updates instantly.
Pets updates instantly.
Optimistic UI
A lot of people are big fans of loaders and spinners. There’s nothing wrong with using a loader; there are perfect use cases where a loader is the best option. I’ve written about loaders versus spinners and their best use cases.
Loaders and spinners indeed play an important role in UI and UX design, but the arrival of Optimistic UI has stolen the spotlight.
What Is Optimistic UI?
Optimistic UI is a convention that simulates the results of a mutation (created data) and updates the UI before receiving a response from the server. Once the response is received from the server, the optimistic result is thrown away and replaced with the actual result.
In the end, an optimistic UI is nothing more than a way to manage perceived performance and avoid loading states.
Apollo Client has a very interesting way of integrating the Optimistic UI. It gives us a simple hook that allows us to write to the local cache after mutation. Let’s see how it works!
Step 1
Head over to client/src/client.js, and add only the highlighted code.
import { ApolloClient } from 'apollo-client' import { InMemoryCache } from 'apollo-cache-inmemory' import { HttpLink } from 'apollo-link-http'import { setContext } from 'apollo-link-context' import { ApolloLink } from 'apollo-link' const http = new HttpLink({ uri: "http://localhost:4000/" }); const delay = setContext( request => new Promise((success, fail) => { setTimeout(() => { success() }, 800) }) ) const link = ApolloLink.from([ delay, http ])const cache = new InMemoryCache() const client = new ApolloClient({ link, cache }) export default client
The first step involves the following:
- We import
setContextfromapollo-link-context. ThesetContextfunction takes a callback function and returns a promise whosesetTimeoutis set to800ms, in order to create a delay when a mutation operation is performed. - The
ApolloLink.frommethod ensures that the network activity that represents the link (our API) fromHTTPis delayed.
Step 2
The next step is using the Optimistic UI hook. Slide back to client/src/pages/Pets.js, and add only the highlighted code below.
..... const Pets = () => { const [modal, setModal] = useState(false) const { loading, error, data } = useQuery(GET_PETS); const [createPet, newPet] = useMutation(NEW_PETS, { update(cache, { data: { addPet } }) { const data = cache.readQuery({ query: GET_PETS }); cache.writeQuery({ query: GET_PETS, data: { pets: [addPet, ...data.pets] }, }); }, } ); const onSubmit = input => { setModal(false) createPet({ variables: { newPet: input },optimisticResponse: { __typename: 'Mutation', addPet: { __typename: 'Pet', id: Math.floor(Math.random() * 10000 + ''), name: input.name, type: input.type, img: 'https://via.placeholder.com/200' } }}); } .....
The optimisticResponse object is used if we want the UI to update immediately when we create a pet, instead of waiting for the server response.
The code snippets above include the following:
__typenameis injected by Apollo into the query to fetch thetypeof the queried entities. Those types are used by Apollo Client to build theidproperty (which is a symbol) for caching purposes inapollo-cache. So,__typenameis a valid property of the query response.- The mutation is set as the
__typenameofoptimisticResponse. - Just as earlier defined, our mutation’s name is
addPet, and the__typenameisPet. - Next are the fields of our mutation that we want the optimistic response to update:
id
Because we don’t know what the ID from the server will be, we made one up usingMath.floor.name
This value is set toinput.name.type
The type’s value isinput.type.img
Now, because our server generates images for us, we used a placeholder to mimic our image from the server.
This was indeed a long ride. If you got to the end, don’t hesitate to take a break from your chair with your cup of coffee.
Let’s take a look at our outcome. The supporting repository for this project is on GitHub. Clone and experiment with it.
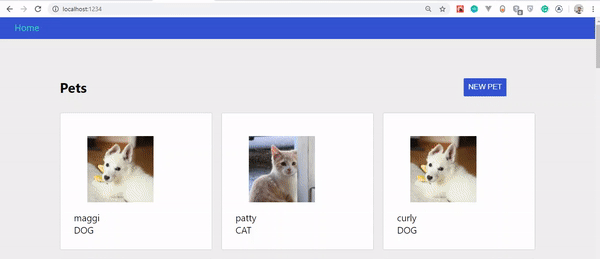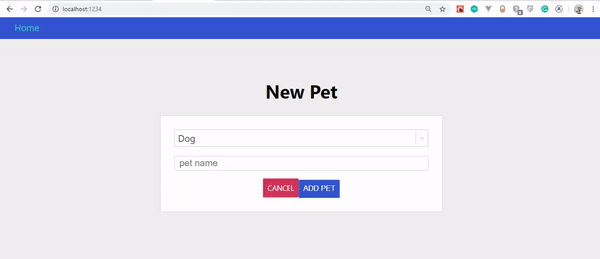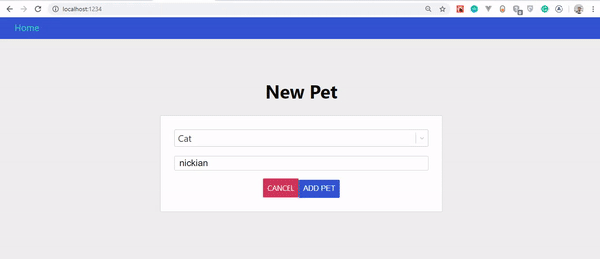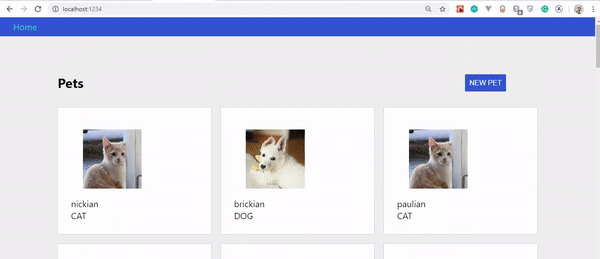 Final result of our app.
Final result of our app.
Conclusion
The amazing features of Apollo Client, such as the Optimistic UI and pagination, make building client-side apps a reality.
While Apollo Client works very well with other frameworks, such as Vue.js and Angular, React developers have Apollo Client Hooks, and so they can’t help but enjoy building a great app.
In this article, we’ve only scratched the surface. Mastering Apollo Client demands constant practice. So, go ahead and clone the repository, add pagination, and play around with the other features it offers.
Please do share your feedback and experience in the comments section below. We can also discuss your progress on Twitter. Cheers!
References
- “Client-Side GraphQL In React”, Scott Moss, Frontend Master
- “Documentation”, Apollo Client
- “The Optimistic UI With React”, Patryk Andrzejewski
- “True Lies Of Optimistic User Interfaces”, Smashing Magazine
Articles on Smashing Magazine — For Web Designers And Developers