Interactive Learning Tools For Front-End Developers
Because this industry moves so quickly, learning new skills is a regular thing for most of us. Over the last little while, I’ve been able to collect links to several interactive coding tools and apps that can help you supplement your skills in different areas of web development.
Whatever you want to learn from CSS to SQL, this categorized list should have you covered. Scroll down for a general overview or skip the table of contents.
- CSS Flexbox
- CSS Grid Layout
- CSS Selectors Cheatsheet
- CSS Animations
- CSS Ruler
- CSS Filters
- CSS Game: CSSBattle
- CSS Game: CSS Diner
- TypeScript
- JavaScript Design Patterns
- React
- JavaScript Game: Elevator
- JavaScript Game: Screeps
- JavaScript Game: Untrusted
- JavaScript Promisees
- JavaScript Game: JSChallenger
- JavaScript Game: JSRobot
- Service Workers
- Git Branching
- SQL
- SQL: SQLBolt
- SQL Police Department
- Regular Expressions
- Regex Crossword
- RegexOne
- Programming Languages, Codewars
- Vim
- Jamstack
If you’re interested in more tools like these ones, please do take a look at the weekly SmashingMag email newsletter, so you can get tips like these drop right into your inbox!
Tools To Learn Flexbox
Flex Box Adventure
Flex Box Adventure is an interactive adventure game allowing you to use your flexbox skills to assist the game character to solve 24 challenges.

Knights Of The Flexbox Table
Knights of the Flexbox Table is another well-designed interactive course to help you learn the different aspects of the flexbox specification. This one includes 18 “dungeons” to teach you flexbox. This course is unique because you’re not writing pure CSS, but instead, you’re using Tailwind CSS classes, which means you’ll learn flexbox along with the syntax for Tailwind utility classes.

Flexbox Froggy
Flexbox Froggy has been around for quite some time and continues to be a popular choice for learning flexbox syntax. Use the different parts of the flexbox spec to arrange the frogs as required to pass the different levels.

Flexbox Zombies
Flexbox Zombies is another educational game to learn flexbox syntax. Each section advances a zombie-related plot while giving you expertise in a new flexbox concept, along with survival challenges that help you use your new flexbox skills.

Flexbox Defense
Flexbox Defense is a play on the ‘tower defense’ strategy game genre that teaches you flexbox through 12 challenges where you have to use flexbox syntax to stop incoming enemies from getting past your defenses.

Flexy Boxes
If you find some of the other flexbox tools a little harder to work with, Flexy Boxes might be a good choice. This is a straightforward flexbox playground that also generates the code for you. Being an older tool, this also provides legacy flexbox code and vendor prefixes but you can select “Vanilla CSS” for the code you’ll use in most cases.

Tools To Learn CSS Grid Layout
Grid Garden
Grid Garden, from Codepip, the same makers as Flexbox Froggy, includes 28 different levels to teach you about the different parts of the CSS Grid Layout specification. And if you’re interested in more from these folks, their Pro plan includes a number of other CSS and JS interactive games.

CSS Grid Cheat Sheet
The CSS Grid Cheat Sheet is a visual and interactive guide to understanding CSS Grid. Select a box in the grid, then use the options and settings in the left sidebar to fiddle with the different parts of the Grid Layout spec.

Grid Attack
Grid Attack is from the same creators as Flexbox Adventure, mentioned earlier. This one isn’t free but includes 80 interactive challenges that are similar to real-world grid layout problems.

Grid Critters
Grid Critters is another interactive challenge-based platform to learn the different parts of the Grid Layout spec in a video-game-like environment. The course includes 10 chapters, each broken down into various levels, some as many as 20-26 levels.

Tools to Learn More CSS Skills
CSS Selectors Cheatsheet
CSS Selectors Cheatsheet is an interactive exercise to test your understanding of CSS selectors. The first few are fairly easy but the exercises increase in difficulty as you get into more advanced selectors like lesser-used pseudo-classes.

CSS Animations
If you want to advance your skills in doing animation on the web, CSS Animations is a solid, full-featured platform for learning and experimenting with the different parts of the CSS animations specification. This 32-part course has lots of pre-built graphics that are used in the course as a basis for the animations. This is a fun way to learn keyframe animations with CSS.

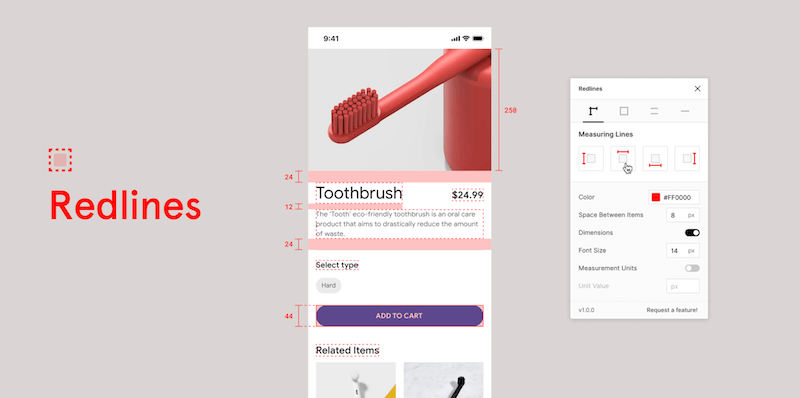
CSS Ruler
CSS Ruler gives you a visual representation of three categories of CSS units you can experiment with: font relative (e.g. rem, ch), viewport percentage (e.g. vh, vw), and absolute (e.g. px, in).

Filter Blend
Filter Blend is a compact little site that lets you mess around with the different values used for CSS’s mix-blend-mode, background-blend-mode, and filter properties. You can add one or more of your own images in layers, along with a background color, then fiddle with the settings to see how the different values behave.

CSSBattle
Admittedly, CSSBattle might be the only interactive learning tool in this list that has the potential to make you a worse developer! This one lets you do interactive challenges where the goal is to use pure CSS to replicate a given image with the least amount of code (i.e. “code golf”). You’ll definitely learn a lot about HTML and CSS with these exercises, but the techniques often won’t be useful in a real-world scenario.

CSS Diner
CSS Diner is great for CSS beginners or those not familiar with advanced CSS selectors. This game allows you to use real CSS selectors on food items with a helpful HTML viewer so you can see the relationship between the graphics and the code.

Tools To Learn JavaScript
TypeScript Exercises
TypeScript Exercises is an interactive playground for fiddling with different features of TypeScript, the popular JavaScript superset that has grown in popularity over the past few years. If you have a rudimentary understanding of TypeScript and want to expand on that, this app might work well for you.

Design Patterns Game
Design Patterns Game is unique and is not for JavaScript beginners. If you have a considerable amount of programming experience or are pretty adept with JavaScript in general, but have never really studied JavaScript design patterns, this might be a good place to start.

React Tutorial
There are lots of places to learn React nowadays and React Tutorial is another good option. What I like about this one is how it starts out with some JavaScript concepts that are important to understand in order to be more effective with React. Also, the in-page editor gives you autocomplete hints as well as hints to solve the challenges. Not all the lessons are free but there’s enough here to get you pretty deep into React’s fundamentals before paying.

Elevator Saga
Elevator Saga is quite different from many of the interactive tools in this list. This one allows you to use JavaScript to program the movement of elevators by means of a built-in API designed for the game itself. So you’ll not only brush up on your JavaScript but also on using a foreign API.

Screeps
Screeps is an open-source massive multiplayer online real-time strategy game that lets you use real JavaScript code to build a colony, mine resources, conquer territory, and more. This one is quite advanced in its gameplay and comes highly recommended by a number of developers and teams.

Untrusted
Untrusted is a JavaScript adventure game where you have to guide a character called Dr. Eval through different mazes. You do so by changing and re-executing the code used for the current challenge to allow Dr. Eval to escape to the next one.

Promisees
Promisees helps you learn a specific part of the ECMAScript spec – JavaScript Promises, a feature that was added to the language in ES6. You can use this little app to visualize how promises work and how they might be used in a real codebase.

JSchallenger
JSchallenger is a simple platform that lets you learn JavaScript by solving different coding challenges. Usefully, this one includes a quick list of “most popular” and “most failed” challenges, so those might be good places to start.

JSRobot
JSRobot is an interactive game where you use JavaScript along with a robot-themed API to control a robot to collect coins, avoid obstacles, and reach the flag at the end of the assigned level.

Service Workies
Service Workies is an interactive adventure game to learn various features for developing Progressive Web Apps (PWAs). This video game-like environment goes through the service worker lifecycle, intercepting requests, working with caches, and more.

Tools To Learn Miscellaneous Web Dev Skills
Learn Git Branching
Visuals are often lacking when learning command-line tools like Git. Learn Git Branching aims to solve that problem with a visual and interactive walk-through of the different features of Git using a Git repository visualizer, sandbox, and a series of educational tutorials and challenges.

Select Star SQL
Select Star SQL allows you to learn SQL concepts. This is done by following instructions that run SQL queries against a real dataset, going through 5 chapters that take approximately 30 minutes each to complete.

Regex101
Regex101 is kind of like JSFiddle for regular expressions, but with some extra features to help you learn to build regular expressions. It includes a regex editor, a library of community-written regular expressions, a quick reference for the syntax, and even an interactive quiz.

SQL Police Department
SQL Police Department lets you learn SQL syntax by solving crimes. Assignments called “briefs” are used as the basis for each crime to solve and the app also includes a guide to help with the syntax if you get stuck.

CodinGame
CodinGame is a full-featured learning platform that allows you to study 25+ programming languages while solving fun challenges.

OpenVim
OpenVim is an interactive tutorial that teaches you how to use Vim, the multi-platform text editor that’s popular among Unix users. If you want more Vim, you can also try vim.so, though that one is not free.

Regex Crossword
Regex Crossword uses crossword puzzle-based challenges to help you learn regular expression syntax. For each challenge, you have to enter a string that’s matched by all the ‘crossed’ expressions.

Codewars
Codewars is yet another platform that helps you improve your skills by solving programming tasks of multiple difficulty levels and for a huge variety of languages, including JavaScript, TypeScript, Python, Ruby, Go, and more.

Jamstack Attack
Jamstack Attack is a series of mini-games to practice different aspects of front-end development.

RegexOne
RegexOne uses a series of about 25 interactive exercises and problems to teach regular expression syntax. Also includes regex guides for 5 different programming languages.

SQLBolt
SQLBolt (same creators as RegexOne) includes 19 simple interactive exercises to gradually teach you how to use SQL.

What Are Your Favourite Interactive Tools?
There are plenty of other interactive learning tools available, and I’m sure many of you have come across some that you’ve found useful. Feel free to post your favorites in the comments below.
Quick Summary
There are plenty of interactive ways to learn new web development skills. Louis shares a comprehensive, categorized list of such tools covering a variety of different development technologies.
Articles on Smashing Magazine — For Web Designers And Developers